Python3 - 开始python编程(七)
在上一篇文章中,我们介绍了类,方法和属性。这些是在代码中创建可重用对象的基本元素,同时还能保持代码干净。在 Python 中经常使用类,因此您需要对该工具有充分的了解。在本文中,我们将研究如何创建类。

初始化
从最基本的意义上讲,Initialization 是为一个类提供一个值。有时,我们希望类在创建时具有默认值,而在其他时候,我们想告诉该类其默认值是什么。
类具有默认的初始化程序,当您不包括自己的初始化程序时,将调用该初始化程序。所有类都是如此,因为它们都派生自对象类型。
之前,我说过class MyClass(object)和class MyClass()是相同的。当您创建一个类时,它是从基类派生的。当您对一个对象进行子类化时,您的子类将从其派生的类继承所有功能。
所有这些都很重要的原因是,当您不创建自己的初始化程序时,初始化依赖于 superclasses(也称为父类)。
我们需要简短地介绍 builtins.py 中的基类 object 来说明这一点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class object:
def __eq__(self, *args, **kwargs):
pass
def __init__(self, *args, **kwargs):
pass
def __new__(self, *args, **kwargs):
pass
def __repr__(self, *args, **kwargs):
pass
def __sizeof__(self, *args, **kwargs):
pass
def __str__(self, *args, **kwargs):
pass
注意:这不是 object 类的所有类方法,只是最常见的。我已将其纤薄,以免您感到不知所措。
__eq__提供执行比较的功能。这个阶级等于另一个阶级吗?使用==运算符时执行。您还可以使用其他对象,例如ne,lt,le,gt和ge`。__init__提供了初始化代码,每当您创建类的新实例时,该代码就会运行。当实例化对象时,它根据需要设置属性的值并调用类的方法。在大多数语言中,这被视为构造方法,但是 Python 确实没有构造方法。但是,它有些接近…__new__与 Python 接近构造函数方法非常接近。 new负责如何创建新对象。虽然简单的示例无法显示此功能,但是当您具有多个子类级别并且需要引导特定对象从特定对象中继承时,它会变得更加常见。 new总是在init之前调用,并且不应包含实例的默认值。__repr__提供了对该类的明确的“正式”字符串引用,默认情况下为`<** main 。MyClass object at 0x100915278>。 **main是此类所在的文件,MyClass 是对象派生的类,0x100915278 处的对象是此对象在内存中的位置,数字是该对象以十六进制开头的块的地址格式。如果您希望使用数据库中某个对象的主键,甚至使用 guid(全局唯一标识符)来唯一地描述此对象,则可以覆盖此方法。__sizeof__很整洁,因为它向我们显示了此对象的字节大小。默认情况下,它是 32 个字节,但是根据此对象保存的数据,它可能会变大。使用my_object.__sizeof__()查找对象的大小,但要记住,任何带有__的东西都不应直接调用,因此应在代码顶部使用import sys并使用sys.getsizeof( my_object)。这实际上为您调用了__sizeof__(),但这是推荐的方法。__str__提供对此分类的“非正式”字符串引用 s。如果不重写此实现,它将提供与repr相同的信息。如果您需要一个友好的类名(在使用str(my_object)时在字符串中使用),那么这里就是这样做的地方。如果不重写__str__,它将提供__repr__的字符串描述。
请放心,如果您认为这些没有任何价值,我们会尽快覆盖这些知识点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Person1:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
def __str__(self):
return self.first_name + " " + self.last_name
charlie = Person("charlie", "brown")
print(charlie) # "charlie brown"
print(repr(charlie) # "<__main__.Person1 object
有了这些知识,我们现在可以了解如何创建类以及所有这些默认功能。

子类化和覆盖
当您更改类的默认实现时,将发生覆盖。 基于上面的 Person 类,如果我们做一些不同的事情怎么办…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class Person1:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
def __repr__(self):
return self.first_name + " " + self.last_name
class Person2(Person1):
def __str__(self):
return self.first_name
daniel = Person1("daniel", "jackson")
jack = Person2("jack", "o'neill")
print(daniel)
print(str(daniel))
print(repr(daniel))
print("--------------")
print(jack)
print(str(jack))
print(repr(jack))
这将产生以下输出…
1
2
3
4
5
6
7
daniel jackson
daniel jackson
daniel jackson
--------------
jack
jack
jack o'neill
这里我们使用Person2(Person1)来将Person1子类化。详细信息与”Person1”相同,但是在”Person2”中,我们不需要调用初始化程序。请记住,Person1将覆盖__repr__方法,而Person2仅覆盖__str__方法。
当我们打印daniel时,我们可以看到,无论我们调用哪种字符串表示形式,我们总会得到daniel jackson。这里没有新内容。
但是当我们称之为”jack”时,我们得到了不同的结果以及关于”print()”如何工作的线索。让我们先看一下实现,然后再返回结果。
我们的init方法丢失了。通过忽略它,Python 会自动在下一个父类中查找一个init方法。由于”Person1”包含一个”init“方法,因此我们使用它并提供”first_name”和”last_name”参数来创建”Person2”类。如果我们有一个没有初始化程序的”Person3(Person2)”类,它将一直返回到”Person1”,以查找默认的初始化程序。
接下来,我们定义了”**str **(self)”,但只返回”self.first_name”,而不是该人的全名。由于存在很小的变化,我们可以查看结果以比较差异。
print(jack)和print(str(jack))都在终端显示jack,这意味着如果我们在 print 语句中不包含str,则print函数会自动调用该类的函数。 。
但是有一点很有趣,当我们使用 print(repr(jack))时,我们得到的是全名,而不是像以前那样在内存中的地址。这必须意味着当我们在repr上调用 print 函数时,我们从 Person1 类中调用了实现。
覆盖仅在一个方向上起作用,如果更改子类的实现,则覆盖只会影响该子类和该子类的其他子类。
如果我将”Person1”中的”repr“更改为”str“会怎样?
“Person1”将不再为该类的每个实例显示友好名称,而是您将在实例所在的内存中看到该地址。但是,打印str(daniel)将打印daniel jackson.
“Person2”将如何受到此影响?
在打印repr(jack)时,Person2也会在内存中打印地址,但是,我们现在从Person1而不是object覆盖__str__,所以我们会看到jack打印在屏幕上,而不是_jack 奥尼尔。

反初始化
在大多数情况下,反初始化是自动进行的。不久之后会更多。反初始化是销毁对象的过程-初始化的逆过程。
从表面上看,这是一个简单的过程。我们所要做的只是调用“对象”继承的类的”del“方法的”del charlie”或”del daniel”。这样会删除指向对象在内存中位置的指针。后来,出现了一个名为garbage collection的过程,就像迪士尼的Wall-E 上的清理机器人一样. Garbage collection 始终在后台运行并在内存中进行扫描以查找缺少引用的对象,然后将这些块设置为free状态,这意味着其他程序可以根据自己的需要使用该内存块。
有时,这需要更多的思考,因此,当我们深入研究反初始化时,我们需要了解其他内容……
参考计数
每当在 Python 中创建类时,都会创建对对象的引用。创建此引用后,系统会与其一起创建一个计数器-该计数器直接引用指向它的对象(包括变量)的数量。
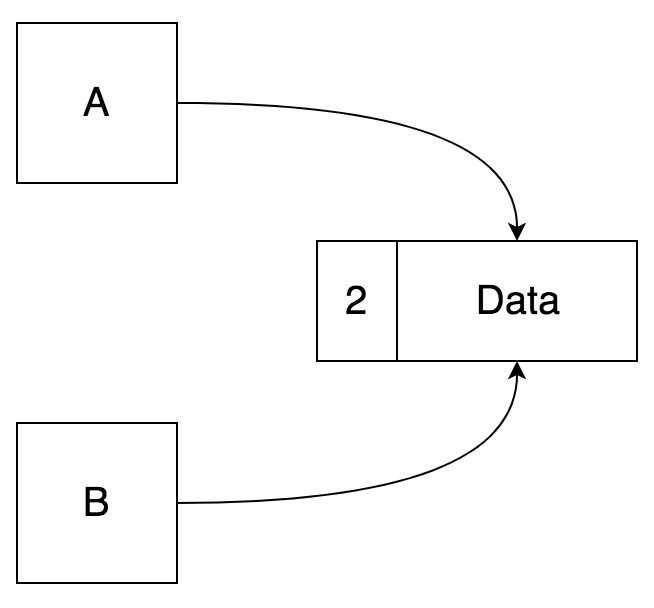
这里我们有两个引用,A 和 B 都指向 Data,所以我们更新计数器以说有两个引用。如果要取消初始化 A,那么我们只有一个对 Data 的引用。
如果 A 和 B 都不再引用数据会怎样?根据内存定律,数据将无限期地存在,或者至少直到计算机关闭之前。
多亏了操作系统,我们不必为此担心太多。在 Python 中,我们有一个称为垃圾收集的工具,该工具可检测 Python 对象之间的循环并计算对我们创建的对象的引用。如果遇到参考计数器设置为 0 的内存块,它将为我们释放该内存。
例:
1
2
3
4
5
6
7
8
9
10
11
class Book:
self.library: Library
class Library:
self.books: dict = {}
my_book = Book()
city_library = Library()
my_book.library = city_library
city_library.books.append(my_book)
在这里,我们有一些被称为循环引用的东西。 “book”知道它属于图书馆,而”city_library”知道拥有”books”字典。
尽管这样的示例在编程中并不常见,但它们可能会发生,因此您需要小心编写代码。
假设”my_book”是第一版,第二版才问世。第一版不再重要,因此图书馆希望抛开它。
如果”city_library”试图删除”my_book”,则无法删除,因为我们仍然可以使用它并对其进行引用。如果我们试图扔掉”my_book”,我们将无法这样做,因为图书馆仍然会为另一个参考计数跟踪它。我们陷入僵局。
因为”my_book”也知道它属于”city_library”,所以”my_book”拥有对该库的引用。因此,我们有 2 个对”my_book”的引用,一个是从我们这里引用的,一个是从库中引用的,还有 1 个对”city_library”的引用,这是由于该书内部印有”city_library”。
如果我们丢掉这本书,图书馆就永远不会知道它,并假设它仍在我们手中。如果图书馆将其从馆藏中删除,我们仍然会拥有它,而其他人可能会认为我们已经偷了它,因为这本书仍然引用了图书馆。
我们如何清除这个问题?
我们需要一次删除一个引用。首先,我们需要与图书馆讨论并制定计划。图书仍在我们手中时,图书馆愿意在柜台与我们合作。
图书管理员首先清除书籍所属图书馆的参考文献,或有效地删除”del my_book.library”,留下 2 个参考文献。
接下来,接下来我们需要删除对这本书的引用,我们使用del my_book上交该书,剩下 1 个引用
最后,图书馆使用del city_library ["my_book"]从其字典中删除条目,并删除最终引用。
垃圾收集开始了,图书馆员把书扔进了垃圾桶。
现在,我们还可以在书上使用一个用弱引用(weakref)定义的东西,表示该标记没有任何意义,但是,该标记仍可用于追溯到特定的库。
示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
import weakref
class Book:
self.library: Library
class Library:
self.books: dict = {}
my_book = Book()
city_library = Library()
my_book.library = weakref.ref(city_library)
city_library.books.append(my_book)
现在,当我们调用del my_book时,对该库的引用将被自动删除,并且对于Book的该实例,city_library和my_book引用都将被删除。 “city_library”所要做的就是从他们的藏书中删除这本书。
使用弱引用可以帮助确保您不必费力找到这样的讨厌的 bug,称为memory 泄漏。当您从不释放内存中的对象并且内存已满时,就会发生内存泄漏。
如今,计算机配备了大量内存,内存泄漏的发生率虽然很少见,但仍会发生。
当我混合音乐时,我使用了一个程序来扫描歌曲,找到歌曲的键,然后将键放在曲目的元数据中。这对于小型收藏集来说效果很好,但是我拥有超过 50,000 首歌曲-大约 40 GB 的音乐,远远超过了计算机中的 RAM。该程序可以播放大约 15,000 首歌曲,然后变慢或崩溃。这是因为它正在打开音乐文件并对其进行强烈引用。
程序中内置了一个故障保护功能,当内存不足时,该功能将触发清除以前扫描的某些文件的引用的功能-足以在再次触发之前处理另外 100 首歌曲。不用说,扫描所有歌曲大约需要 2 1/2 天,而本可以在 8 小时左右完成。
如果您需要更多示例,以及对强参考周期的更好解释,请查看Artyer 的 Stack Overflow 帖子。
摘要
今天,我们了解了更多有关如何创建类,它们来自何处,如何覆盖它们的功能,如何摆脱它们,引用周期以及内存泄漏的知识。这是一些学习-坚持不懈!
建议阅读
另外,在第 11.6 弱引用的信息。
下一步是什么
接下来是格式化,lambda 和列表理解。格式化可能已经很久了,但是我认为它很容易掌握。列表理解要稍微困难些,但仅在语法和使用它们的不同方式上。
Lambda 将成为主要焦点,因为它们可能最令人困惑。
总的来说,我们将学习制造单行代码的新方法。