Python3 - 开始python编程(十四)
在上一篇文章中,我们介绍了asyncio,只是介绍了异步代码的表面。今天,我们将通过研究另一种称为多线程的方法来继续朝着异步的方向发展。如果您还没有阅读上一篇文章,强烈建议您阅读介绍作为入门。

让我们放大一秒钟,然后再考虑一下全局。
- 进程(Process)—运行以执行工作的单个程序。 (例如 Google Chrome,Firefox)
- 线程(Thread)—程序向其发送任务的工作者queue。
- 线程队列(Thread Queue)-处理器将以先进先出(FIFO)方式处理的指令列表。 (想想工厂线)
- 堆栈(Stack)-您调用的所有表达式都将向线程队列发送指令。这些都是以后进先出(LIFO)的方式创建的。 (想想如何在不将其撞倒的情况下一一拆毁一幢积木)
- 内存空间(Memeroy Stack)-单个进程使用的内存空间,一个进程可以访问该进程可以拥有的所有线程,该线程拥有该进程拥有的所有线程。
多线程(Threading)
虽然asyncio可能适用于 Web 服务器,但有时它并不是完成这项工作的最佳工具。如果您回头看前一篇文章,当您与多个资源有许多连接(也就是 Web 服务器路由)时,asyncio很有用。但是,如果您需要与单个资源建立一些连接,例如同时处理硬盘驱动器上的文件,会发生什么?
线程可以共享内存和资源,因为它们属于(属于)同一进程。
进程无法共享内存或资源,因为它们属于自己的内存空间。如果确实需要在两个进程之间共享数据,则需要将此数据存储在数据库或缓存中。
这是threading库进入的地方。
threading在不同的线程上产生进程。我们不仅可以使用“线程”来执行同时的文件操作,还可以使用它来执行多个下载请求或多个 API 调用。
在进入示例之前,还要介绍的另一项内容是”race condition“。竞争条件是两个单独的进程或线程试图同时操作相同数据时的情况。发生这种情况时,一个进程可能会获得意外数据。如果您阅读了我的上一篇文章并运行了最后一个示例,您将在控制台输出中看到竞争情况。有些行似乎已合并。虽然它不会使我们的程序崩溃,但在许多情况下,您的程序都会崩溃。使用threading库时,重要的是要跟踪正在修改的内容和时间。如果有帮助,请将其写下来。
让我们看一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import threading
def count(thread, min, max, result):
print(f"Thread {thread}: started")
this_list = []
index = 0
for i in range(min, max):
this_list.insert(index, i)
index += 1
result.insert(thread - 1, this_list)
print(f"Thread {thread}: completed")
results = []
thread1 = threading.Thread(target=count, args=(1, 0, 10000000, results))
thread2 = threading.Thread(target=count, args=(2, 0, 1000000, results))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(f"\n{len(results[0])}")
在这里,我们在文件顶部导入threading以使用该库。然后,我们创建一个函数,该函数返回一个列表,该列表包含我们传入的 min 和 max 参数之间的每个值。当前正在运行的线程。
在我们的 count 函数中,我们首先打印出线程已启动。我们创建一个”this_list”变量来保存值,并将”index”变量初始化为 0。
然后,我们使用范围的”min”和”max”值遍历所有值,并将它们插入数组中,同时增加索引。然后我们打印出线程已完成,然后再向外部result变量中添加my_list以便以后打印。
接下来,我们创建两个线程,并为每个线程提供count目标。目标是我们要在此线程上执行的操作。由于t t 考虑三个参数,我们还将三个参数作为元组传递给 args 关键字。
这是两个线程不同的地方。一个从零到一百万_,而另一个从零到一百万。在我的测试中,这些是理想的数字,可以证明这两个线程同时运行而无需花费太多时间。如果速度太快或在计算机上花费的时间太长,可以随意在每个数字中添加或删除零。
仅仅因为我们创建线程并不意味着它们启动,我们就必须在每个线程上调用”start()”以使其运行。这有助于比赛条件。有时您可能想在一次启动所有线程之前枚举需要使用的所有线程(例如,将线程存储在自己的列表中,然后遍历列表调用每个线程的 start)。
最后,我们使用 thread.join()阻塞主队列,以确保得到结果。然后,在“结果”列表中打印第一个列表的长度。
请注意,如果尝试在单核 CPU 上使用多线程,则不会看到性能提升。相反,您可能会因为尝试处理异步代码同步的单个处理器开销而导致性能下降。

线程池执行器 (ThreadPoolExecutor)
有时您需要自定义一个任务应使用多少个线程,例如限制在一系列任务中应使用的并发线程数。
为了说明这一点,请看下面的示例,它只是上面示例的重构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from threading import Thread
def count(thread, min, max, result):
print(f"Thread {thread}: started")
this_list = []
index = 0
for i in range(min, max):
this_list.insert(index, i)
index += 1
print(f"Thread {thread}: completed")
result.insert(thread - 1, this_list)
results = []
threads = []
for i in range(4):
threads.append(Thread(target=count, args=(i, 0, 10000000 * i, results)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print(f"\n{len(results[0])}")
在这里,我们最终创建四个不同的线程来处理相同的数据。我只是决定使用循环来管理一次又一次地重写相同代码的复杂性(DRY 原理)。
假设我们有多个任务需要在后台线程上运行。这些任务中的每一个都需要一些初步信息,这些信息必须在相应任务开始之前完成。一个基本的网络爬虫将是一个很好的例子。
在小型网站上,我们可能可以使用threading来解决问题,但是在大型网站上,我们绝对需要限制正在使用的线程数,以免出现性能问题。你只能走得这么快。
这是一个基于此处的示例的使用 ThreadPoolExecutor 的重构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
mport threading
import time
from concurrent.futures import ThreadPoolExecutor
numbers = range(100000, 1000000, 10000)
def task(number):
print(f"Executing new Task on thread {threading.current_thread().name[-3:]}")
result = 0
for i in range(number):
result = result + i
print(f"Result: {result}")
print(f"Task Executed on thread {threading.current_thread().name[-3:]}")
def main():
executor = ThreadPoolExecutor(10)
executor.map(task, numbers)
if __name__ == "__main__":
current_threads = threading.active_count()
start_time = time.time()
main()
while threading.active_count() > current_threads:
pass
print("\n\nCOMPLETE\n--- Took %s seconds ---" % (time.time() - start_time))
我们在顶部还有更多的进口。我们包含threading是因为我们需要在程序启动时获取active_count()线程,并且需要能够弄清楚当前正在为任务使用哪个线程。之所以包含“时间”,是因为我们希望在调整使用的线程数时计算应用程序的运行时间。最后,我们从并发中使用。futuresimport ThreadPoolExecutor 允许我们独家地导入 ThreadPoolExecutor,而不是整个 concurrent 库。这就是我们稍后将要调用的执行程序,以运行所有任务。
我开始创建一个“数字”列表,该列表将包含 100,000 到 1,000,000 之间的值(以 10,000 为增量)。我们将使用它在运行之间将一致的值传递给每个任务。我最初从使用随机库中的 randint 开始,但意识到一次运行可能只获得低值,而另一次可能获得高值。这会歪曲我们的结果。
然后我们创建我们的任务。这类似于上面的 count 函数,除了我们传入了我们想用作最大数的数字。我们让所有人都知道我们在新线程上启动了任务并提供了名称。由于名称为”ThreadPoolExecutor-x-y”,其中”x”是当前线程池,而”y”是当前线程,所以我仅使用字符串的最后三个值。
我们将result初始化为 0,然后开始循环以对所有数字求和。我们在打印”current_thread()”完成之前打印“结果”。
接下来是我们的主要功能。在其中,我们首先从 ThreadPoolExecutor 中创建一个 executor 对象,传入希望使用的最大工人数。我们也可以通过使用命名参数”max_workers = 10”来做到这一点。如果将此保留为空白,则最终将计算机上的处理器数量乘以 5。在我的计算机上,我有 8 个逻辑处理器*5 个线程= 40 个线程。
通常,我们会为每个任务调用 executor.submit(task),但是在这种情况下,我们会将变量传递给函数,在这种情况下,我们使用 executor.map(task,numbers)来为我们完成所有这些工作。发生的情况是,解释器首先检查以获取“数字”的长度,然后针对“数字”中的每个数字,将值传递给“任务”的“数字”参数。一旦完成,它将随后使用executor来完成任务。
然后,我们有if __name__ =="__main __"语句,该语句检查是否调用了该文件。最初创建该程序时,我没有包括下一行,该行获取了当前活动线程的数量,当我打印活动线程数时,发现该程序已经使用了三个线程。
因此,我需要获取活动的线程数,以便可以防止程序立即在底部运行经过时间的行。将此视为基本的信号量,该信号量用于确保多个线程的同步。 Python 具有这些内置功能,但是示例更易于以这种方式进行消化。
向下移动,我得到了当前时间,因此我们可以计算出以后的经过时间。然后,我调用main(),它开始了我们应用程序的业务逻辑。一旦完成所有工作,我们将确定经过的时间(以秒为单位)并将其打印到屏幕上。
在对各种数字进行了一些测试之后,我对数字进行了一些数据科学实验,以显示所使用的线程数与运行时间之间的相关性。
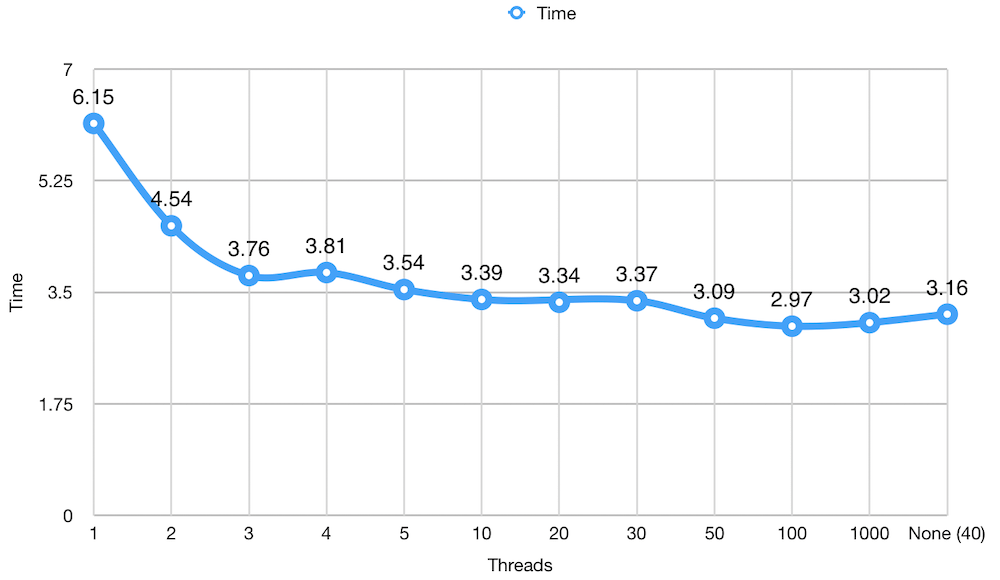
所用线程总数的运行时间(以秒为单位)。
在上图中,您可以看到我们如何在六秒钟开始以一个线程运行上面的示例。随着线程数量的增加,我们很快就会看到运行时间减少。在四个线程处,我们看到了更糟糕的时间,我多次运行该示例以确保没有异常,并且我不断获得一致的结果。随着我们继续增加线程数,我们看到了以毫秒为单位的稳定增长,然后稳定在 10 到 30 个线程之间。
跳到 50,我们看到另一个提升,在 100 个线程中,我们看到了最佳运行时间。使用 100 个线程并不理想,因此我们应该退后一步,考虑 30 到 50 之间的范围。
有趣的是,当我们传递 1000 个线程时,我们的时间变得更糟。造成这种情况的最可能原因是启动所有 1000 个线程所需的时间。在这种情况下,更多并不是更好。
最后,通过不向 ThreadPoolExecutor()传递任何数字来使用默认数量的工作线程,我们看到了 3. 16 秒。这比 50 个线程还差,但是在我们的例子中,它看起来还不错。
根据要创建的线程池数量,我可能会使用 40–50 作为划分工作线程数量的基准。我还将参考此图来确定每个池使用的最佳线程数。如果需要三个池,则可以给每个十个工作线程。如果使用 12 个池,则我可能会选择每个池三个线程而不是四个线程,因为我的运行时间更好,为三个。
从另一个角度来看,我可以为需要更多工作才能完成的池提供更多线程,而为那些需要执行基本任务的线程提供更少的线程。我还可以通过优先级分配更多的线程来分配线程,这些任务是作为守护程序运行的用户必须等待的任务,或者使用一两个线程运行的后台任务。参考上面的图表,我可以将三个线程用于所有后台任务,而我可以将 5 或 10 用于用户启动的所有任务。我需要确保将其限制在更广泛的范围内(可以是 50 或 100)。
摘要
我们使用threading模块和concurrent模块介绍了 Python 中的多线程。我们简要介绍了如何创建和管理线程以及如何在继续执行程序之前等待线程完成。
关于线程和线程池的更多详细信息,我在这里没有介绍。我只是想让您的脚在穿线时弄湿,所以您在阅读文档时不会感到迷路。
建议阅读
来自 Python 文档的线程。
线程化-基于线程的并行性-Python 3.7.4rc1 文档
parallel.futures —启动并行任务— Python 3.7.4rc1 文档
下一步是什么?
接下来是多进程。多进程就像多线程,只是我们使用多个内核来执行工作。我们还将在结尾处讨论异步,线程和多处理之间的差异。了解每个任务要使用哪一个至关重要。在此之前,请继续练习。